A robust chronic obstructive pulmonary disease classification model using dragonfly optimized kernel extreme learning machine
- Select a language for the TTS:
- UK English Female
- UK English Male
- US English Female
- US English Male
- Australian Female
- Australian Male
- Language selected: (auto detect) - EN
Play all audios:

ABSTRACT Chronic obstructive pulmonary disease (COPD) is considered to be one of the most commonly occurring respiratory disorders and is proliferating at an extremely high rate in the
recent years. The proposed system aims to classify the various stages of COPD using a COPD patient dataset comprising 101 patients and 24 varied factors related to the disease. In addition,
a self-acquired dataset containing 560 lung CT images was also used. The obtained hybrid database is normalized, augmented, and preprocessed using bilateral filter and contrast enhanced
using dynamic histogram equalization. Segmentation is then performed using SuperCut algorithm. Feature extraction is done by binary feature fusion technique involving UNet and AlexNet.
Kernel extreme learning machine-based classification is conducted further, and the results produced are optimized using dragon fly optimization algorithm. The proposed system produced an
enhanced accuracy of 98.82%, precision of 99.01%, recall of 94.98%, F1 score of 96.11%, specificity of 98.09%, MCC value of 94.33%, and AUC value of 0.996 which are far better when compared
with other existing systems. SIMILAR CONTENT BEING VIEWED BY OTHERS GREYLAG GOOSE OPTIMIZATION AND MULTILAYER PERCEPTRON FOR ENHANCING LUNG CANCER CLASSIFICATION Article Open access 10
October 2024 TRISPECTRAKAN: A NOVEL APPROACH FOR COPD DETECTION VIA LUNG SOUND ANALYSIS Article Open access 21 February 2025 A 3D-CNN MODEL WITH CT-BASED PARAMETRIC RESPONSE MAPPING FOR
CLASSIFYING COPD SUBJECTS Article Open access 08 January 2021 INTRODUCTION Chronic Obstructive Pulmonary Disease (COPD) is estimated to become the third largest disease which causes
mortality across the globe in the year 20301. The main concerns of this disease to the medical faculties are. * a. it is not completely curable. * b. It can only be treated throughout the
lifetime of the patient, and * c. it can become worse at any point of time. It is a non-communicable disease that has been increasing year after year because of the alarming rise of
pollutants in the air and smoking habits. The disease is also considered to be in its peak stage after the onset of the coronavirus disease since the pandemic has left various disturbances
on human lungs. A recent study reveals that around 24 million people are affected by this disease annually in the United States and also half of them go undiagnosed and succumb to the deadly
disorder2. Traditional diagnosis of COPD is becoming difficult even with the numerous advancements in medical sciences. The main reason behind this fact is the common symptoms that the
disease shares with other respiratory disorders and it can be easily misdiagnosed3. Hence there arises a huge need for an automated system that identifies and classifies the various stages
of COPD depending upon the severity. Also, the economic burden that the disease places on its patients is exceedingly high and is estimated to be around 6% of the European Union’s financial
budget annually. It is a heterogeneous disease that involves numerous smaller respiratory disorders. It is usually caused by the continuous exposure of the air tract and the lungs to micro
particles that is often toxic and allergic4. It has four distinct stages classified by the Global initiative for chronic Obstructive Lung Disease (GOLD) such as stage 1, stage 2, stage 3,
and stage 4. While the first stage is considered to be mild and the second one moderate, stages 3 and 4 are considered to be severe and very severe in nature. As the disease progresses,
symptoms such as breathlessness, cough, dyspnea, and exacerbations intensify5. Although many imaging modalities such as magnetic resonance imaging, ultrasound and computed tomography images
are available, specialists believe that the CT images of the affected lungs will function as the proper base for the identification of COPD. Various other signals such as electromyography
signals, sounds of breathing etc. can also be used for identifying the disease. By identifying the disease in earlier stages, we can prevent the disease from progressing to further stages
and also reduce the costs associated to the treatment. Research on COPD has been happening in different directions such as. * a. Proper identification and classification of the grade of the
disease, * b. Measures to control the progression of the disease from one stage to the next one, * c. Various biological markers that can indicate the risk of predicting the disease prior to
its onset and * d. Also, studies are conducted in order to separate this disease from the associated diseases that are similar in nature to COPD6. * e. The effect of active and passive
smoking, differentiation of patients living in rural and urban areas in order to analyze the aftermath of air pollution are also under study. Artificial Intelligence (AI) and deep learning
have been widely applied in the field of medical diagnosis and have been quite successful over the years7. Medical practitioners have stated that AI has indeed helped them a lot in the
identification and treatment of several heart and brain related diseases. Thereby applying deep learning to pulmonary diseases should also prove to be fruitful. In order to keep a check on
the upward sloping curve of COPD, it is essential that a computerized and automated system is developed that can aid the medical professionals especially the pulmonologists in the early
identification of the disease. The main contributions of the proposed work are. * The proposed work gathers a hybrid dataset including CT lung images and patient dataset from Kaggle website.
The obtained dataset is augmented, bilateral filtered and contrast enhanced using dynamic histogram equalization. * Segmentation is performed using SuperCut algorithm and binary feature
fusion process is conducted by concatenating UNet and AlexNet techniques. * Classification is done using KELM to categorize the COPD disease into four different grades. The results are
further optimized using multi objective Dragonfly optimization algorithm for improving the performance. * Statistical analysis is conducted to evaluate the classification performance of the
KELM model using accuracy, precision, recall, F1-Score, specificity, MCC, ROC and AUC values. * Comparative study with existing systems such as Logistic Regression, Random Forest, Recurrent
Neural Network, Long Short-Term Memory, and Inception V3 is done to prove the enhanced performance of the proposed work. The paper in organized as follows. A thorough investigation of
similar works on COPD grade classification are presented in Sect. “Related works”. Detailed description of proposed model is given in Sect. “Proposed system”. Experimentation and results are
discussed in Sect. “Results and discussion”. Concluding remarks are given in Sect. “Conclusion”. RELATED WORKS The work in literature8 describes about the severity analysis of chronic
obstructive pulmonary disease utilizing multi-channel lung sounds and training them with deep learning models. The authors have used the RespiratoryDatabase@TR which has 12 different sounds
of the lung, 4 sounds related to the heart along with spirometry and chest X-rays of 41 patients. Abnormalities were detected using cuboid quantization and octant quantization coupled with
the second order difference chaos plot. Deep extreme learning machines were used to classify the five different severities of the disease that used Hess and Lu autoencoder kernels. The
proposed system achieved an accuracy of 94.31%, sensitivity of 94.28%, specificity of 98.76% and area under the curve value was around 0.9659. The authors of9 and10 have highlighted about
the usage of ensemble learning approach for the analysis of pulmonary diseases like COVID-19, tuberculosis, and pneumonia using automated chest X rays. In both the articles, they have stated
the efficiency of using deep learning and machine learning models in the process of identifying diseases in the medical domain. Data was initially augmented and then resized and converted
to gray scale for further processing. Features were extracted using histogram of oriented gradients (HOG) and local binary pattern (LBP) techniques. VGG-16, DenseNet-201, and Efficient-B0
models are involved in the classification process achieving an accuracy of 98%. The research work carried out in11,12,13,14,15,16 describes about the detection process of lung nodules using
convolutional neural networks, InceptionNet-V3 and weighted filters. The classification results are further optimized using grey wolf optimization algorithm. The proposed system achieved an
accuracy of 98.33% sensitivity of 100% and specificity of 93.33%. LIDC-IDRI dataset is used here. The images are converted into jpeg format and adaptive filtering is applied to remove any
noise present. Features are then extracted using Greywolf optimization and then Inception-V3 classifier is applied to classify the input images into three cases such as normal, benign or
malignant. Findings in17 present a machine learning based CT imaging model that is used to mark the difference between the diseases of COPD and asthma. Patients suffering from both diseases
were employed for this analysis from the Heidelberg University Hospital in Germany. 93 features related to both the diseases such as low attenuation cluster, estimated thickness of the
airway, perimeter of the airway, total count of the airway etc. were collected. The dataset included 48 COPD patients and 47 asthma patients. Several pulmonary function tests that evaluated
the forced expiratory volume and forced vital capacity were calculated and CT images of the lung were also collected. Machine learning algorithms were trained with hybrid features and
implemented in Python 3.7.3 version and Matlab R2019. The data set was preprocessed using normalization and Z-score standardization. Training and testing data were split in the ratio of
70:30. Barlett’s sphericity and Kaiser–Meyer–Olkin metrics were used to analyze the classification outputs. Particle swarm optimization was also used on the classified results for
betterment. The chosen classifier was the support vector machine and features whose eigenvalues were greater than 1 and the Pearson correlation coefficient greater than 0.9 was used for the
analysis. The system produced an accuracy of 80%, sensitivity of 87%, specificity of 71% and F1-Score of 81%. The authors of18 have provided a comparative study of the CT images in the task
of classifying the spirometric severity of COPD utilizing deep learning techniques. 80 patients participated in the study for whom post-bronchodilator pulmonary function test was taken. A
total of 26,794 images were collected and they were preprocessed by resizing them to 512*512 pixels and rotating them from -25 to 25 degrees. Only those images that satisfied the threshold
value of 950 in the lung field were considered for further processing. During feature extraction, parameters such as age, sex, body mass index, smoking habits, FVC, FEV, reversibility,
capacity of diffusing Carbon monoxide were extracted. Statistical analysis was conducted by building a confusion matrix. Two class and four class analysis were also performed using
McNemar–Bowker test. Authors in19 have developed a system that performs automatic classification of CT images into different Emphysema using varied deep learning methods. The authors have
come up with a retrospective cohort study involving 10,192 patient that have smoked in the past. 2407 were used for training the classifier, 100 for parameter tuning and the remaining 7143
were used for testing purpose. Features like ratio of FEV and FVC, dyspnea score, walking ability, sex, race, height, weight, and smoking history were collected. Feature extraction was done
with the help of convolutional neural network and classification was done by long short-term memory. Paper20 presents a new multimodal system that is capable of identifying and classifying
the disease of COPD and other multivariate pulmonary diseases such as tuberculosis, bronchitis, upper and lower respiratory tract infection using CT scan images. Three techniques namely the
fusion model using machine learning and deep learning, cough sample method that uses the lung sound and CT scan based identification model were employed in the study which gave accuracies of
97.50%, 95.30% and 98% respectively. From this, the authors have concluded that diagnosis and classification of COPD using CT images prove to be the best way. The research work in21 shows
the identification and classification of COPD patients and their application using the Rome severity model. The study involved 364 patients who were hospitalized at the Maastricht University
Medical center. All of them were diagnosed with COPD along with exacerbations. According to the reports 14.3% of patients had grade 1 COPD, 56.0% had grade 2 COPD and 29.7% had grade 3
COPD. This paper performs a post hoc analysis of an already published data using characteristics such as age, locality, gender, stage of GOLD, residential information, Charlson index, status
of smoking etc. Shapiro–Wilk normal test, ANOVA test, Fisher’s exact test and Tukey’s test were performed on the dataset using IBM SPSS software tool version 28.0 for both parametric and
non-parametric data. The authors of22 have studied the overlap between the diagnosis done by a machine learning algorithm and pulmonologists. The study involves 400,000 pulmonology patients
from five different countries. 360 respiratory professionals were also included in the review process. This study was done to test the diagnostic performance of the machine learning tool and
compare it with that of actual doctors. Factors that were considered for the case study were FEV, ratio between FEV and FVC, pack years of smoking, height weight ratio, dyspnea, cough and
wheezing, condition of rhinitis, therapies undergone etc. The detection accuracy achieved by the AC/DC tool was 73% and by the pulmonologists was 61%, which proves the superior performance
of the machine learning models. 23 presents a research work regarding the multi-omics classification of the COPD disease using deep learning graphs models. For the identification of the
disease, convolutional graph neural network and protein protein interaction networks were used. AhGlasso algorithm was applied on String PPI database and COPD gene dataset. Analysis on gene
ontology revealed that heparin signaling and carbohydrate derivative signaling were major factors in classification of COPD. Findings of24 show the anomaly based quantitative evaluation of
CT images in the classification and prediction of the severity grades of COPD. The authors have used four deep learning models such as recurrent neural network, multiple instance learning
(MIL), MIL combined with RNN and attention-based MIL model. Data was acquired from COPD gene dataset and Cosyconet cohort study including 446 patients. Information regarding demographics,
spirometry and smoking were taken as the prime factors. The prediction score was evaluated using linear mixed models. PROPOSED SYSTEM The proposed KELM based COPD classification system
utilizes a hybrid dataset consisting of CT images of the affected lungs and COPD patient dataset from Kaggle website. The database contains 101 patient details pertaining to 24 factors
related to the disease such as Forced Expiratory Volume(FEV), Forced Vital Capacity(FVC), atrial fibrillation, ability to walk, smoking habits, diabetes, hypertension, pack history of
smoking, COPD Assessment Test(CAT) score, HIV Associated Dementia(HAD), St.George’s Respiratory Questionnaire(SGRQ) and Ischemic Heart Disease(IHD). 560 CT images were self-acquired from a
reputed hospital. While both the datasets are sufficient individually for classifying the various grades of COPD, combining them would indeed improve the classification performance to a
great extent. Since the acquired images are not sufficient for conducting the proposed system execution, they are augmented using method of rotation, horizontal flipping, vertical flipping,
scaling, and translation. The augmented images are then preprocessed using bilateral filter and contrast enhanced using dynamic histogram equalization method. The patient database is
normalized using outlier rejection and redundancy removal. After this, the filtered images are segmented using SuperCut algorithm. Binary feature fusion is performed using UNet and AlexNet.
Once the features are extracted from both the techniques, they are concatenated to arrive at the feature vector. Classification is conducted with the help of Kernel extreme learning machine
classifier. The results are further optimized using Dragon fly optimization algorithm for maximizing the classification accuracy of the proposed system. Performance metrics such as accuracy,
precision, recall, F1 score, Matthew’s Correlation Coefficient (MCC), Receiver Operating Characteristic (ROC) curve and Area Under the Curve (AUC) are calculated and further compared with
existing systems of Logistic Regression, Random Forest, Recurrent Neural Network, Long Short-Term Memory and InceptionV3. In real time, the proposed system can be used as an aid to help
medical professionals in the processing of identifying and grading the disease of COPD. Classifying the specific grades of the disease would support in choosing the ideal and right modes of
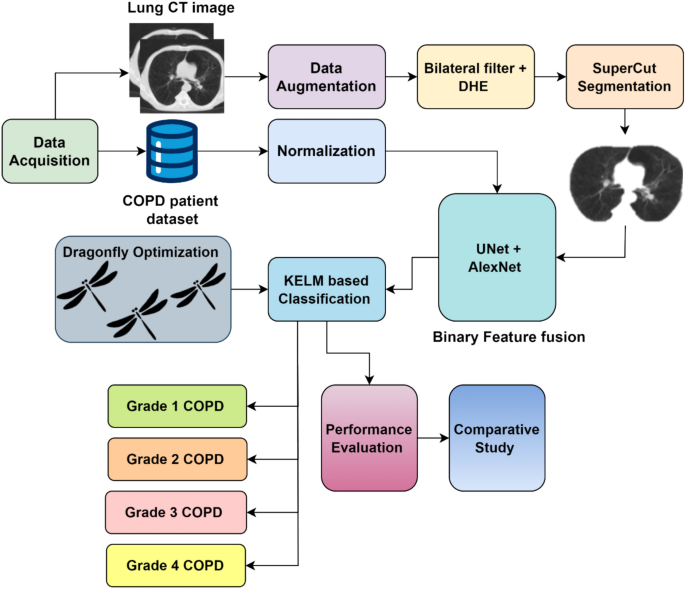
treatment for the patient and would also reduce the cost incurred and time involved. Figure 1 shows the workflow of the proposed model in an illustrative manner. DATA ACQUISITION The
proposed system makes use of a hybrid dataset that combines the COPD patient dataset along with affected CT images. The patient dataset was obtained from Kaggle website link
https://www.kaggle.com/datasets/prakharrathi25/copd-student-dataset containing the disease details of 101 COPD patients. It includes 24 varied factors related to the disease and other health
parameters of the patient like FVC, FEV, atrial fibrillation, ability to walk, smoking habits, diabetes, hypertension, pack history of smoking, CAT score, HAD, SGRQ and IHD values. In
addition to this, 340 CT images are also acquired for training and evaluating the proposed KELM classifier. The images were divided in the ratio 80:20 in order to train and evaluate the
classification performance of the chosen classifier. DATA AUGMENTATION Since the acquired CT images are less in number and will not be sufficient to proceed further, the input images are
augmented using method like rotation, horizontal flipping, vertical flipping, scaling, and translation. The chosen data augmentation techniques like rotation, horizontal flipping, vertical
flipping, scaling, and translation offer generalized results that are much useful for the classification process. These methods are much easier to process and also help in providing robust
performance. In this way, 220 new images were produced which totals up to 560 CT images. The details of the data augmentation parameters are given in Eqs. (1–6) below. $$A_{n} \left( {a,b}
\right) = \frac{{A\left( {a,b} \right) - {\text{min}}\left( A \right)}}{{\max \left( A \right) - {\text{min}}\left( A \right)}}$$ (1) A—image selected, min(A) and max(A) are the minimum and
maximum pixel values, \(A_{n}\) represents the normalized image. $$A_{r} \left( {a,b} \right) = A_{n} \left( {a cos\theta - b sin\theta , a sin\theta + b cos\theta } \right)$$ (2) $$A_{hf}
\left( {a,b} \right) = A_{n} \left( {a, Q - b - 1} \right)$$ (3) $$A_{vf} \left( {a,b} \right) = A_{n} \left( {P - a - 1,b} \right)$$ (4) $$A_{s} \left( {a,b} \right) = A _{n} \left(
{\frac{a}{s},\frac{b}{s}} \right)$$ (5) $$A_{t} \left( {a,b} \right) = A_{n} \left( {a + \Delta a, b + \Delta b} \right)$$ (6) where \(A_{r} \left( {a,b} \right)\) represents the rotation,
\(A_{hf} \left( {a,b} \right)\) stands for horizontal flipping, \(A_{vf} \left( {a,b} \right)\) denotes vertical flipping, \(A_{s} \left( {a,b} \right)\) represents scaling and \(A_{t}
\left( {a,b} \right)\) stands for translation tasks. PREPROCESSING As there are two types of input data, they are preprocessed separately. The COPD patient dataset is normalized using
outlier rejection and redundancy removal techniques so that the repeated values and unwanted data are eliminated. Any missing data is filled using averaging method. Once the patient dataset
is normalized, the CT images are preprocessed using bilateral filter and contrast enhanced using dynamic histogram equalization. BILATERAL FILTER The main problem with linear filters is that
they tend to remove and filter out the edges that are surrounded by the noise in the process of filtering noise25. This leads to loss of vital information. In order to overcome this issue,
a non-linear filter was designed that is capable of removing noise without blurring out the nearby edges. This filter was later called as the bilateral filter which can perform noise removal
and still preserve sharp edges. This property is achieved because the bilateral filter is based upon the radiometric variations of the image pixels such as intensity of colors, depth etc.
in addition to the calculation of Euclidean distance. The proposed system uses bilateral filtering method as it possess several added advantages when compared to other type of filtering
techniques such as easier usage and has simple parameters to deal with. It does not work in an iterative manner which makes it computationally very fast. Edge preservation and noise
reduction properties of the image are very effective with the application of this filter. It has three components for working such as the factor of normalization, space, and range weights.
In addition to the observation of neighboring pixels extent and size, it also calculates the amplitude differences of sharp edges. This is done to make sure that the pixels which are in
range with the mid value are blurred excluding the pixels whose intensity does not match with the central one, thereby indicating it as an edge and thus preserving it. The working of the
bilateral filter has been given below in Eqs. (7–11). $$bl_{f} \left[ i \right] = \frac{1}{{O_{P} }} \mathop \sum \limits_{q \in S} S_{{\sigma_{s} }} \left( {\left| {\left| {g - h} \right|}
\right|} \right)R_{{\sigma_{r} }} \left( {\left| {i_{g} - i_{h} } \right|} \right) i_{h}$$ (7) $$E\left( i \right) = k_{i}^{ - 1} \mathop \sum \limits_{{a \in R_{b} }} B_{r} \left( {C_{ab} }
\right) \times W_{s} \left( {D_{ab} } \right) \times F\left( i \right)$$ (8) $$k_{i} = \mathop \sum \limits_{{a \in R_{b} }} B_{r} \left( {C_{ab} } \right) \times W_{s} \left( {D_{ab} }
\right)$$ (9) $$B_{r} \left( {C_{ab} } \right) = exp\left( {\frac{{C_{ab}^{2} }}{2} \times \sigma_{r}^{2} } \right)$$ (10) $$W_{s} \left( {D_{ab} } \right) = exp\left( {\frac{{D_{ab}^{2}
}}{2} \times \sigma_{s}^{2} } \right)$$ (11) where Op is the factor of normalization , g and h mean the pixel coordinates, \(S_{{\sigma_{s} }}\) is the space parameter and \(R_{{\sigma_{r}
}}\) is the range parameter, \(k_{i}^{ - 1}\) stands for the output , \(B_{r} and W_{s}\) denote the kernel weights, \(C_{ab}\) and \(D_{ab}\) indicate the Euclidean distance. DYNAMIC
HISTOGRAM EQUALIZATION (DHE) Dynamic histogram equalization was chosen because it has the ability to elevate the contrast and quality of the image to a great extent without adding much to
the computational complexity of the process. It can also shed light on minute details of the image thereby leading to better classification performance. It is an iterative algorithm that
partitions the histogram of the image under consideration and creates numerous sub histograms26. The equalization process stops when all the partitioned histogram shares the same level of
contrast. Firstly, histogram is calculated and depending upon the local minimum points, it is sub divided. The task of partitioning continues until no dominating areas are found. Then for
each of the produced sub histograms, gray levels are allocated. The allocation is done based on the cumulative distribution function value and gray range that may be present in the output
image. The range and span are calculated using the below Eqs. (12) and (13). $$gray_{s} = lm_{s} - lm_{s - 1}$$ (12) $$gray_{r} = \frac{{gray_{s} }}{{\sum gray_{s} }}*L - 1$$ (13) where
\(gray_{s}\) is the gray level span, \(gray_{r}\) is the gray range, lm is the local minimum, L is the end limit. This contrast range division prevents the overpowering of high elements over
the small ones thus ensuring maintenance of each and every image detail. Lastly, the sub histograms are equalized separately using a transformation function that ensures the pixel range
equality thus outputting an image that is contrast enhanced in a dynamic manner. It can be applied for images that require both local and global contrast enhancements and it assures that no
information is lost or hidden during the entire process. This type of histogram equalization is better than others because it does not introduce any checkerboard effect in the image and also
does not change the clarity and appearance of the image. SUPER CUT BASED SEGMENTATION SuperCut algorithm is the integration of SuperPoint and CUT algorithms. It was designed to combine the
efficiency and advantages of both the techniques. It is unsupervised in nature and works on the principle of Bayes decision theory27. It falls under the category of interactive image
segmentation algorithms which makes it even more powerful and popular. The application of SuperCut based segmentation over other usually preferred segmentation approaches, is because of the
user interactive nature of this method. It has the capability to produce improved segmented images that marks it different from that of the others. It solves the problem of getting stuck in
local minimum points as it happens in its predecessors of GrowCut and GrabCut. The images are pre-segmented into super pixels and accurate boundaries based on the application of Bayes
theory. For pre- segmenting, mean shifting algorithm which is confident about the boundaries is used. The segmented super pixels are grouped into effective clusters based on the Bayes
decision theory. Gaussian mixture model is later applied combined with an interactive rectangular box for assigning the boundaries of the objects that have been segmented so far. This is
done to achieve more accurate edges and arrive at a solution for unclear boundaries. Secondary clustering of pixels is done again with the help of the chosen rectangular box. An energy
function is also used for this purpose whose Eq. (14) is given below. $${\text{E}}\left( {{\text{ec}}} \right) \, = \sum E_{1} \left( {ec_{i} } \right) + \lambda \sum E_{2} \left( {ec_{i} ,
ec_{2} } \right)$$ (14) where E(ec) is the energy consumption, _i_ and _j_ are pixels that are adjacent to each other. Pixels are classified into foreground or background based on its
position with respect to the bounding box. Those pixels which lie outside the box are considered to be in the background and vice versa. Equations (15–17) give the feature vector of the
probable foreground and background objects. $${\text{P }}[{\text{bcg}}|{\text{s }}\left( {{\text{p}},{\text{ q}}} \right)]{ } = \frac{{{\text{P}}\left[ {{\text{s}}\left(
{{\text{p}},{\text{q}}} \right){\text{|bcg}}} \right]P\left( {bcg} \right)}}{{{\text{P}}\left[ {{\text{s}}\left( {{\text{p}},{\text{q}}} \right)} \right]}}$$ (15)
$${\text{P}}[{\text{fg}}|{\text{ s}}\left( {{\text{p}},{\text{q}}} \right)]{ } = \frac{{{\text{P}}\left[ {{\text{s}}\left( {{\text{p}},{\text{q}}} \right){\text{|bcg}}} \right]P\left( {fg}
\right)}}{{{\text{P}}\left[ {{\text{s}}\left( {{\text{p}},{\text{q}}} \right)} \right]}}$$ (16) where bcg is the background, \({\text{s}}\left( {{\text{p}},{\text{q}}} \right)\) is the set
of features and fg is the foreground. $${ } {\text{P}}[{\text{bcg}}|{\text{s}}\left( {{\text{p}},{\text{q}}} \right)\left] { \, > {\text{ P}}} \right[{\text{fg}}|{\text{ s}}\left(
{{\text{p}},{\text{q}}} \right)]$$ (17) The final feature vector is given by Eq. (18). $${\text{P}}\left[ {{\text{s}}\left( {{\text{p}},{\text{q}}} \right)} \right] = {\text{P}}\left[
{{\text{s}}\left( {{\text{p}},{\text{q}}} \right){\text{|bcg}}} \right]P\left( {bcg} \right) + {\text{P}}\left[ {{\text{s}}\left( {{\text{p}},{\text{q}}} \right){\text{|fg}}} \right]P\left(
{fg} \right)$$ (18) BINARY FEATURE FUSION Feature extraction is conducted using two different techniques namely UNet and AlexNet machine learning algorithms. The main reason for choosing
UNet and AlexNet methods as feature extractors is the segmentation efficiency that both the techniques possess. The output of both the methods are fused together to form the desired feature
vector. UNET It is a contemporary model of CNN that is fully connected. The specific advantage of UNet architecture is the fine-tuned object boundary identification that helps to a great
extent in the further processing of the image. It is also very prompt in its working and can deal well with large images too. It gains its name from its U-shaped appearance that arises due
to the presence of an ascending and descending network. These two networks take the role of an encoder and decoder28. There are four encoder parts and four decoder parts both of which is
connected by a bottleneck layer and skip connections tie the networks together. In total there are nine blocks that contract initially and then expand thus enabling superior feature
extraction. The encoder attempts to mitigate the spatial information present and augment the feature information within the image. This task is accomplished with the help of a ma pooling
layer, rectified linear unit layer and several 3*3 convolutions. The down sampled image is again up sampled by the decoder that performs transpose 2*2 convolution operations and a single 1*1
convolution at the end to produce the required number of feature channels. The introduction of feature channels is considered the reason behind the massive success of U-Net architecture.
The expanding network combines the spatial and feature information produced by the contracting path using a series of up convolutions. Information is passed between the encoding and decoding
channels using skip connections. They are located in between the convolution layers and hence facilitate flow of information back and front. Both the networks are similar to each other in
many aspects. Figure 2 shows the structure of UNet. The energy function of the feature channels is given by the Eqs. (19) and (20). $$F = \mathop \sum \limits_{p = 1}^{N} g\left( t
\right)log\left( {s_{l\left( t \right)} \left( t \right)} \right)$$ (19) $$s_{l} = exp\left( {a_{l} \left( y \right)} \right)/\mathop \sum \limits_{{l^{\prime} = 1}}^{L} exp\left( {a_{l}
\left( t \right){\prime} } \right)$$ (20) where \(F\) is the energy function, \(t\) stands for the features extracted, \(g\) represents the weight, \(s_{l}\) denotes the function of SoftMax,
l is the channel and \(a_{l}\) is for channel activation. ALEXNET AlexNet is modern type of convolutional neural network that has won the visual challenge of recognition of images
containing almost 14 million images29. It is a phenomenally successful model that has been employed for different image processing tasks such as segmentation, feature extraction, pattern
recognition, image classification etc. The major advantage of AlexNet is its capacity to extract precise and complicated features from the underlying image with the help of the deep layers
present in its architecture. The architecture of AlexNet contains eight different layers of convolution, fully connected layers, max pooling and ReLu functions. Layers of drop out and
response normalization are also present. It is amazingly fast in computation and takes input of the size 227*227*3. The architecture has been designed in a deep style where the first layer
of convolution contains 96 filters of size 11*11. The output produced is of the size 55*55*96. Max pooling layers are of the general size of 3*3. Mathematical expressions for AlexNet model
are given in Eqs. (21), (22) and (23). $$f_{i} = fm*k_{i} + b_{i}$$ (21) where fm is the feature map, b is the bias and k are the convolutional kernel. Activation function is represented as
$$AF_{i,j} = a\left( {\mathop \sum \limits_{c = 0}^{D - 1} \mathop \sum \limits_{e = 0}^{s - 1} \mathop \sum \limits_{g = 0}^{s - 1} w_{c,e,g} fm_{i + c,j + e,g} + b} \right)$$ (22) \(i,j\)
is location of the feature map. Pooling operation in AlexNet is represented as $$p_{i,j,k} = L_{{\left( {c,e} \right) \in R_{i,j} }} \left( {fm_{c,e,g} } \right)$$ (23) R stands for pooling
region and \(L\) indicates the pooling function. Second layer has even more filters of 256 but with a reduced capacity of 5*5. ReLu activation function is used here, and padding operation is
conducted to obtain an output of 27*27*256. The next convolution layer makes use of 384 filters of size 3*3 and the feature map produced is 13*13*384. Fourth layer is exactly similar to
third layer but with an additional padding done30. The final layer contains 256 filters of size 3*3. There has been a huge increase in the number of filters from 96 to 384 in order to
achieve better features. The size of the filters has been correspondingly reduced for the same purpose. The next set of layers is the fully connected ones with 4096 and 1000 neurons with a
dropout factor of 0.5. Finally, a softmax classification function is added. KELM BASED CLASSIFICATION Kernel Extreme Learning Machine (KELM) is a kind of Extreme Learning Machine (ELM) which
is nothing but a feed forward network that has three layers namely the input layer, hidden layer, and output layer31. There are many variations in the design of ELM, one of which is the
kernel extreme learning machine which uses a kernel for mapping the input to output. These machines are considered to be far better than the artificial neural networks and are considered to
produce better results and classification performance. KELM has many added benefits when compared to traditional classification methods like Support Vector Machine (SVM). SVM does not have
the potential to handle large datasets and also suffers from the problem of outlier interference. Random forest model requires a lot more of memory space and sometimes extensive time also
for classification. KELM on the other hand are computationally inexpensive, fast in terms of classification and are very handy to implement without requiring any additional human expertise.
The regular algorithms belonging to the family of artificial neural networks suffer from many problems because of using back propagation and gradient descent-based algorithms which causes
them to get stuck in the local minima often. Because of its superior classification results and fast learning, it has a wide range of applications in different fields of research32. It can
be widely used for the purpose of classification, regression, clustering, learning, and mapping features, approximation, and prediction. Researchers have stated that extreme learning machine
algorithms reach the global optima in a faster manner and do not get stuck in the local minima like the traditional neural networks. The data from the input layers are randomly mapped to
the hidden layers and this causes slight variations in the accuracies produced at the output layer in each iteration. In order to get rid of this problem, the KELM was introduced which maps
the input to the hidden layer using an orthogonal projection-based calculation. The number of hidden layers can be one or many depending upon the architecture chosen. The nodes in the hidden
layers are the actual computational engines that perform the task under consideration. The propagation of data from the hidden layer to the output layer is conducted with the help of a
nonlinear activation function, mostly the rectified linear unit is used. The activation function is given as in Eq. (24). $${\text{f}}\left( {\text{W}} \right){ } = {\text{ max}}\left\{
{0,{\text{W}}} \right\}{ } = { }\left\{ {\begin{array}{*{20}c} { 0 , if W_{i,j} < 0 } \\ {W_{i,j} otherwise } \\ \end{array} } \right.$$ (24) The working of kernel extreme learning
machine has two basic steps33. The first is the initialization of parameters that is done in a random manner and next is arriving at an analytical solution using activation functions like
sigmoid functions, hyperbolic tangent functions, radial basis functions, quadratic functions etc. and using the Moore Penrose generalized inverse. Classification is then done based on the
mapping of input to the output class with the maximum similarity. The output function is given by the Eq. (25), $$\mathop \sum \limits_{i = 1}^{H} k_{i} \left( x \right)\beta_{i} = b_{i}$$
(25) where \(\left( {a_{i} ,b_{i} } \right)\) is the training data and \(H\) is the nodes present in the hidden layers. In the above equation \(k_{i} \left( x \right)\beta = b_{i}\) can be
rewritten as \(K\beta = S\), where \(\beta\) is the weight of the output vector. $$HL = \left[ {\begin{array}{*{20}c} {k\left( {a_{1} } \right)} \\ \vdots \\ {k\left( {a_{n} } \right)} \\
\end{array} } \right] = \left[ {\begin{array}{*{20}c} {k_{1} \left( {x_{1} } \right)} & \cdots & {k_{H} \left( {a_{1} } \right)} \\ \vdots & \ddots & \vdots \\ {k_{1} \left(
{x_{n} } \right)} & \cdots & {k_{H} \left( {a_{n} } \right)} \\ \end{array} } \right]$$ (26) The sum of least squares solution given by the ELM classifier can be calculated as
$$\tilde{\beta } = H^{L + }$$ (27) \(HL^{ + }\) stands for the Moore Penrose generalized inverse. Similarly, the objective function is given as below in Eqs. (28–30). $$minimize:HL\beta -
S$$ (28) $$minimize:H_{{P_{ELM} }} = \frac{1}{2}\beta^{2} + D\frac{1}{2}\mathop \sum \limits_{i = 1}^{N} \xi_{i}^{2}$$ (29) $$h\left( {x_{i} } \right)\beta = t_{i}^{T} - \xi_{i}^{T} , i =
1,2, \ldots , N$$ (30) The final classification mapping of input to output is done by the following Eqs. (31) and (32). $$\hat{U} = V_{o } W = V_{o } f\left( {V_{i } Z} \right)$$ (31)
$$\hat{u} = \arg {\text{ max}}\hat{U}$$ (32) where \(Z\) is the input matrix, \(U\) is the one hot label representation of the input, \(V\) is the hidden to output layer matrix and \(W\) is
the activation function. The error that occurs in the complete process can be formulated as in (33). $$error = \mathop \sum \limits_{a = 1}^{m} ||g_{a} - o_{a} ||^{2}$$ (33) where \(g\) is
the ground truth and so are the output. DRAGONFLY OPTIMIZATION ALGORITHM This meta-heuristic, multi objective optimization algorithm is inspired from the swarming behavior of dragon flies.
The proposed work aims to utilize the potential of dragonfly optimization technique in the classification of COPD dataset. The biggest profit that this technique yields is the adaptability
and ease of implementation. It is a widely used optimizer for various real world problems and can search for solutions globally. While genetic algorithms suffer from a variety of
disadvantages like getting stuck in the local minima, additional cost of computation incurred and inefficiency in handling multifaceted datasets, Dragonfly optimizer solves all of these
shortcomings easily. Dragon flies fall under the category of small predators and follow two swarming patterns called as the feeding swarm and migratory swarm34. The former swarming pattern
is also known as the static swarming consists of feeding on local preys using abrupt movements and rapid change of flying path. The second type of swarming called as the dynamic or migratory
swarm comprises a huge population of dragon flies flying over long distances in a particular direction. Researchers have taken inspiration from these behaviors of the dragon flies and have
constituted an optimization algorithm that can be binary or multi objective in nature. It can be used for solving discrete and also continuous problems. Because of its ease of computation
and the ability of attaining a global optimum point minimally, this optimization algorithm is frequently used over the few years. The two swarming patterns of dragon fly are similar to the
optimization characteristics of exploitation and exploration in nature. This algorithm consists of five factors such as separation, alignment, cohesion, attraction, and repulsion. Separation
refers to the concept of avoiding conflicts with neighbors. Alignment is defined as the process of maintaining the same velocity of speed by all the individuals in the group. Cohesion
refers to the principle of moving towards the center of the population. The other two common principles are the attraction and repulsion with reference to the location of dragon flies and
source of food and predator35. The mathematical formulations for all the five principles are given below in Eqs. (34–38). $$S_{a} = \mathop \sum \limits_{b = 1}^{NB} y - y_{b}$$ (34)
\(S_{a}\) stands for the separation factor, y is the current position, and NB is the number of neighbors. $$A_{a} = \frac{{\mathop \sum \nolimits_{b = 1}^{NB} L_{b} }}{NB}$$ (35) \(A_{a}\)
is the alignment factor, L is the velocity of the bth neighbor. $$C_{a} = \left\{ {\frac{{\mathop \sum \nolimits_{b = 1}^{NB} y_{b} }}{NB} - y} \right\}$$ (36) \(C_{a}\) stands for cohesion
here. $$att_{a} = \left\{ {y^{ + } - y} \right\}$$ (37) \(att_{a}\) is the attraction and \(y^{ + }\) is the location of the food. $$rep_{a} = \{ y^{ - } + y\}$$ (38) \(rep_{a}\) is the
repulsion factor and \(y^{ - }\) is the location of the predator. Figure 3 shows the illustration of these factors of dragonfly. Two vectors called as the step vector and position vector are
updated in an iterative manner depending upon the current location of the dragon flies as shown in Eqs. (39) and (40). During the exploitation phase which reflects the static swarming
behavior of the dragon flies, weights are assigned in such a way that cohesion has low values and alignment has high scores. Similarly, during the exploitation phase which is similar to the
dynamic swarming pattern of the dragon flies, weights are assigned accordingly so that alignment has low value and cohesion has high value36. Food and enemy are also considered to be crucial
factors in this algorithm which are denoted by F and E. Along with this, the neighbors also play an especially key role and therefore the neighboring space radius (NR) in and around each
dragonfly is considered. It is essential that we need to balance the two phases of exploration and exploitation by tuning the factors of swarming during the various iterations of the
algorithm. As the optimization algorithm progresses, it is necessary that the dragon flies change their weights, flying path and neighboring radius accordingly. $$\Delta y_{t + 1} = \left(
{w_{1} S_{a} + w_{2} A_{a} + w_{3} C_{a} + w_{4} att_{a} + w_{5} rep_{a} } \right) + ia\Delta y_{t}$$ (39) \(w_{1} , w_{2} , w_{3} , w_{4} , w_{5}\) are the weights of the corresponding
factors, ia is the weight of inertia and t is the no. of iteration. $$y_{t + 1} = \left( {y_{t} + \Delta y_{t + 1} } \right)$$ (40) This updating of the swarm factors will converge at some
point to arrive at the final stage of optimization where the best solutions can be found37. In order to guarantee the random nature of the dragon flies, this algorithm uses a new parameter
called as the levy flight which is just a random walk of the dragonfly where there are no viable solutions around. The following Eq. (41) can be used during the levy flight phase to update
the position vector of the dragon fly. $$y_{t + 1} = \left( {y_{t} + y_{t} .Levy\left( d \right)} \right)$$ (41) where levy can be defined as in Eq. (42). $${\text{Levy}}\left( {\text{d}}
\right) = 0.01{ }\frac{{e_{1} .\sigma }}{{\left| {e_{2} } \right|^{\beta } }}$$ (42) \(e_{1} and e_{2}\) are the range values and \(\beta\) is constant. The calculation for \(\sigma\) is
given in (43). $$\sigma = ( \frac{{\beta ! .(\sin \frac{\pi \beta }{2})}}{{\left( {\frac{\beta - 1}{2}} \right)!.\beta .2^{{\frac{\beta - 1}{2}}} }} )^{{\frac{1}{\beta }}}$$ (43) RESULTS AND
DISCUSSION The proposed system is implemented within the environment of python including pre-defined libraries of TensorFlow and Keras. 560 self-acquired CT lung images were divided in the
ratio 80:20 for KELM classifier training. 448 images are used for training the classifier and 112 images for evaluating it. For grade 1 COPD, 104 images were used to train the classifier,
and 30 images were used for testing. For grade 2 COPD, 113 images were utilized for training and 25 for testing. Similarly for grade 3 and 4, 131 and 157 images were employed in total. The
details of dataset division are given in Table 1 below. Figure 4 shows the sample view of the COPD Patient dataset collected from the Kaggle website. Figure 5 shows the sample CT images of
patient’s lungs affected by COPD. Table 2 below the details of data augmentation processes along with the range values. The images are rotated to 180 degrees and scaling factor is around
0.25. Both horizontal and vertical flipping is performed to create new images and the augmentation process of translation is also carried out. Figure 6 shows the bilateral filtered and DHE
based contrast enhanced lung CT images. SuperCut algorithm-based segmentation results are shown in Fig. 7. Table 3 lists the details of the simulation parameters chosen for the appropriate
execution of the proposed system. The size of the population is 50 with a learning rate of 0.01. The number of hidden units in the classifier is 256 and the rate of dropout is 0.3. Batch
size is 32 here, no. of epochs is 200, no. of iterations is 100 and size of kernel is 5 for the chosen classifier. The classification performance of the proposed KELM model is calculated
using evaluation metrics of accuracy, precision, recall, F1-Score, specificity, Matthew’s Correlation Coefficient (MCC), Receiver Operating Characteristic (ROC) curve and Area under the
Curve (AUC) values. They reflect the actual performance of the classifier model, concentrate on negative instances too and thus evaluate the quality of the classifier in a much better
manner. Table 4 shows the performance scores that have been achieved by the proposed system during training and testing phases. The proposed dragonfly optimized KELM classifier produced an
accuracy of 98.82%, precision of 99.01%, recall of 94.98%, F1 score of 96.11%, MCC score of 94.33%, specificity of 98.09%, ROC value of 0.95 and AUC score of 0.996. The training and
validation accuracy curve is presented in Fig. 8 and training and validation loss curve is given in Fig. 9. Accuracy is rising with each increasing epoch and touches a peak value of 98.91%
during the training phase and the training loss values follow a steep descending order. Figure 10 shows the analysis of precision and recall scores. The average precision value is definitely
above 0.991 which indicates the phenomenal performance of the proposed model. The average precision value for grade 1 of COPD is 1.00, grade 2 is 0.998 grade 3 is 0.991 and grade 4 COPD is
1.00. Table 5 shows the values of the precision scores attained by the proposed KELM classifier at regular intervals. It also compares the precision values scored by existing systems such as
Logistic Regression (LR), Random Forest (RF), Recurrent Neural Network (RNN), Long Short-Term Memory (LSTM) and InceptionV338. At epoch 50, the proposed system reaches 92.5 and at epoch
100, it attains a precision score of 93.1. Likewise, after the 150th epoch, 97.3 score is achieved and the final precision value attained by the KELM classifier is 99.01. Figure 11 shows the
comparison of precision with respect to the other models under study in an illustrative manner. The precision value of the proposed KELM model is very much superior to that of the other
ones hence proving the optimal performance of the chosen classifier. Table 6 provides the details of the recall values scored by the proposed model at regular epoch intervals such as the
50th epoch, 100th epoch, 150th epoch and 200th epoch and existing systems as well39. As the epoch value increases, the recall score also increases. After 50 cycles of epoch, the proposed
model scores 91.9 and at epoch 100, it reaches 92.4. At the 200 epoch, the final recall value hits 94.98 which show the improved performance of the proposed system over the other models.
Figure 12 depicts the comparison graph of recall values achieved by the proposed system and existing classifiers of COPD. It is evident from the figure that the recall value scored by the
proposed system is better than all of them. The values of F1 score achieved by the proposed model are listed in Table 740. After 50 epochs, the proposed model attains 93.8 and at epoch 100,
F1 score is 94.9. Similarly, at the 150th and 200th epochs, the values are 95.2 and 96.11, respectively. The relative analysis of F1 score is shown in Fig. 13. Like other performance
metrics, the F1 score recorded by the proposed KELM model is better. Table 8 shows the values of the MCC scores attained by the proposed and existing systems41. MCC scores are shown only for
selected four epochs namely 50th, 100th, 150th and 200th epoch. The scores are 89.6, 92.4, 93.1 and 94.33, respectively. Figure 14 explains the scores of MCC values accomplished by the
chosen and existing classifiers. The proposed system performs better and higher in terms of MCC score amongst the others. Table 9 shows the details of the proposed and existing algorithms
specificity values attained at four selected epochs42. After the 50th epoch, the specificity score of the proposed KELM model is 94.5. During the 100th, 150th and 200th epoch, the
specificity values are 95.1, 96.7 and 98.09. Figure 15 illustrates in a graphical manner the detailed analysis of scores of specificities attained by the proposed system and compares them
with the rest of the models under study. Table 10 specifies the accuracy details of the proposed and existing algorithms43. After the 50th epoch, the accuracy value of the proposed KELM
model is 93.8. Then after running for another 50 epochs, accuracy becomes of 94.6. During the 150th and 200th epoch, the values are 97.1 and 98.82, respectively. Figure 16 below depicts the
accuracy analysis of the proposed system in comparison with the existing classifiers. It can be seen from the figure that the classification performance of the proposed Dragonfly optimized
KELM model is far better than the existing deep learning techniques. Figure 17 shows the ROC curve attained by the proposed system that uses KELM classifier and dragonfly optimization
algorithm. ROC is a graphical showcase of the classification performance of the classifier at different threshold values. It is a measure of true positive and false positive rates attained
by the classification model. The AUC values attained by the different grades of COPD are 0.999, 0.994, 0.998 and 1.000 for grade 1, grade 2, grade 3 and grade 4 of COPD, respectively. The
average AUC of the proposed model is 0.996 which is considered to be particularly good. The ROC curve and its corresponding AUC values show the superior performance of the classifier model
chosen for the disease classification of COPD. CONCLUSION Chronic obstructive pulmonary disease is becoming a global threat to mankind that needs to be curbed immediately. The proposed
kernel extreme learning machine-based classifier coupled with dragon fly optimization technique used a hybrid dataset to identify different grades of COPD. In this process, it uses state of
the art techniques such as bilateral filter, dynamic histogram equalization, SuperCut and binary feature fusion involving UNet and AlexNet. The proposed KELM classifier achieves an accuracy
of 98.82%, precision of 99.01%, recall of 94.98%, F1 score of 96.11%, specificity of 98.09%, MCC value of 94.33% and AUC value of 0.996. The comparative analysis of the proposed system with
existing COPD classification models such as logistic regression, random forest, recurrent neural network, long short-term memory, and inception V3 shows that the proposed dragon fly
optimized KELM classifier outperforms all the other models and produces enhanced classification results. In future, the model can be extended to incorporate huge datasets and identify more
complicated pulmonary disorders to aid medical professionals. The potential limitation of the proposed work would be minor changes in the rate of accuracy when the model is generalized to
larger and diverse datasets. DATA AVAILABILITY The patient dataset was gained from Kaggle website link https://www.kaggle.com/datasets/prakharrathi25/copd-student-dataset containing the
disease details of 101 COPD patients. CODE AVAILABILITY The custom code and algorithm developed for the COPD classification system—including the Dragonfly Optimization module, Kernel Extreme
Learning Machine (KELM), SuperCut segmentation, and binary feature fusion using UNet and AlexNet—are part of an ongoing research dissertation and forthcoming project proposal. Due to
institutional policy and the preliminary nature of this work, the code is not publicly available at this stage. However, it may be shared by the corresponding author upon reasonable request
for academic and non-commercial research purposes. REFERENCES * Zhang, L., Jiang, B., Wisselink, H. J., Vliegenthart, R. & Xie, X. COPD identification and grading based on deep learning
of lung parenchyma and bronchial wall in chest CT images. _Br. J. Radiol._ 95(1133), 20210637 (2022). Article PubMed PubMed Central Google Scholar * Wu, Y. et al. A vision transformer
for emphysema classification using CT images. _Phys. Med. Biol._ 66(24), 245016 (2021). Article Google Scholar * Sundar Raj, A., Naidu, P. C., Sivakumar, S. & Senthilkumar, S. Hybrid
attention residual deep convolution learning network for bio medical image analysis. _J Intell. Fuzzy Syst._ 48(4), 537–554. https://doi.org/10.3233/JIFS-241512 (2025). Article Google
Scholar * S. Senthilkumar, S. Vetriselvi, K. Kalaivani, P. Arunkumar, M. Malathi, S. Praveen Kumar, “Super-resolution image using enhanced deep residual networks and the DIV2K dataset”,
_Proceedings of the Second International Conference on Self Sustainable Artificial Intelligence Systems (ICSSAS-2024),_ 23 and 24 Oct 2024. https://doi.org/10.1109/ICSSAS64001.2024.10760961.
* Park, J. et al. COPDGene investigators. Subtyping COPD by using visual and quantitative CT imaging features. _Chest_ 157(1), 47–60 (2020). Article PubMed Google Scholar * Hasenstab, K.
A. et al. Automated CT staging of chronic obstructive pulmonary disease severity for predicting disease progression and mortality with a deep learning convolutional neural network. _Radiol
Cardiothor Imaging_ 3(2), e200477 (2021). Article Google Scholar * Fraiwan, M., Fraiwan, L., Alkhodari, M. & Hassanin, O. Recognition of pulmonary diseases from lung sounds using
convolutional neural networks and long short-term memory. _J. Ambient Intell. Human. Comput._ 1, 1–3 (2022). Google Scholar * Altan, G., Kutlu, Y. & Gökçen, A. Chronic obstructive
pulmonary disease severity analysis using deep learning onmulti-channel lung sounds. _Turk. J. Electr. Eng. Comput. Sci._ 28(5), 2979–2996 (2020). Article Google Scholar * Amin, S. U.,
Taj, S., Hussain, A. & Seo, S. An automated chest X-ray analysis for COVID-19, tuberculosis, and pneumonia employing ensemble learning approach. _Biomed. Signal Process. Control_ 87,
105408 (2024). Article Google Scholar * Hussain, A. et al. An automated chest X-ray image analysis for covid-19 and pneumonia diagnosis using deep ensemble strategy. _IEEE Access_ 11,
97207–97220 (2023). Article Google Scholar * Bilal, A. et al. IGWO-IVNet3: DL-based automatic diagnosis of lung nodules using an improved gray wolf optimization and InceptionNet-V3.
_Sensors._ 22(24), 9603 (2022). Article ADS PubMed PubMed Central Google Scholar * Bilal, A., Sun, G., Li, Y., Mazhar, S. & Latif, J. Lung nodules detection using grey wolf
optimization by weighted filters and classification using CNN. _J. Chin. Inst. Eng._ 45(2), 175–186 (2022). Article Google Scholar * Li, H. et al. Carlos Molina Jimenez, “UCFNNet:
Ulcerative colitis evaluation based on fine-grained lesion learner and noise suppression gating”. _Comput. Methods Programs Biomed._ 247, 108080 (2024). Article PubMed Google Scholar *
Wang, W. et al. Advancing aggregation-induced emission-derived biomaterials in viral, tuberculosis, and fungal infectious diseases. _Aggregate._ 6(3), e715. https://doi.org/10.1002/agt2.715
(2025). Article CAS Google Scholar * Chen, S. et al. Evaluation of a three-gene methylation model for correlating lymph node metastasis in postoperative early gastric cancer adjacent
samples. _Front. Oncol._ 14, 1432869. https://doi.org/10.3389/fonc.2024.1432869 (2024). Article CAS PubMed PubMed Central Google Scholar * Pu, X., Sheng, S., Fu, Y., Yang, Y. & Xu,
G. Construction of circRNA–miRNA–mRNA ceRNA regulatory network and screening of diagnostic targets for tuberculosis. _Ann. Med._ https://doi.org/10.1080/07853890.2024.2416604 (2024). Article
PubMed PubMed Central Google Scholar * Moslemi, A. et al. Differentiating COPD and asthma using quantitative CT imaging and machine learning. _Eur. Respirat. J._ 60(3), 213070 (2022).
Article Google Scholar * Sugimori, H., Shimizu, K., Makita, H., Suzuki, M. & Konno, S. A comparative evaluation of computed tomography images for the classification of spirometric
severity of the chronic obstructive pulmonary disease with deep learning. _Diagnostics_ 11(6), 929 (2021). Article CAS PubMed PubMed Central Google Scholar * Humphries, S. M. et al.
Genetic epidemiology of COPD (COPDGene) investigators. Deep learning enables automatic classification of emphysema pattern at CT. _Radiology_ 294(2), 434–444 (2020). Article PubMed Google
Scholar * Kumar, S. et al. A novel multimodal framework for early diagnosis and classification of COPD based on CT scan images and multivariate pulmonary respiratory diseases. _Comput.
Methods Progr. Biomed._ 1(243), 107911 (2024). Article Google Scholar * Reumkens, C. et al. Application of the Rome severity classification of COPD exacerbations in a real-world cohort of
hospitalised patients. _ERJ Open Res._ 9(3), 569 (2023). Article Google Scholar * Kocks, J. W. et al. Diagnostic performance of a machine learning algorithm (asthma/chronic obstructive
pulmonary disease [COPD] differentiation classification) tool versus primary care physicians and pulmonologists in asthma, COPD, and asthma/COPD overlap. _J. Allergy Clin. Immunol. Pract._
11(5), 1463–1474 (2023). Article PubMed Google Scholar * Zhuang, Y. et al. Deep learning on graphs for multi-omics classification of COPD. _PLoS ONE_ 18(4), e0284563 (2023). Article CAS
PubMed PubMed Central Google Scholar * Almeida, S. D. et al. Prediction of disease severity in COPD: a deep learning approach for anomaly-based quantitative assessment of chest CT.
_Eur. Radiol._ 34(7), 4379–4392 (2024). Article PubMed Google Scholar * Wang, C. et al. Comparison of machine learning algorithms for the identification of acute exacerbations in chronic
obstructive pulmonary disease. _Comput. Methods Programs Biomed._ 188, 105267 (2020). Article PubMed Google Scholar * Wang, Q., Wang, H., Wang, L. & Yu, F. Diagnosis of chronic
obstructive pulmonary disease based on transfer learning. _IEEE Access_ 8, 47370–47383 (2020). Article Google Scholar * Asatani, N., Kamiya, T., Mabu, S. & Kido, S. Classification of
respiratory sounds using improved convolutional recurrent neural network. _Comput. Electr. Eng._ 94, 107367 (2021). Article Google Scholar * Polat, Ö., Şalk, İ & Doğan, Ö. T.
Determination of COPD severity from chest CT images using deep transfer learning network. _Multimed. Tools Appl._ 81(15), 21903–21917 (2022). Article Google Scholar * Mondal, S., Sadhu, A.
K. & Dutta, P. K. Automated diagnosis of pulmonary emphysema using multi-objective binary thresholding and hybrid classification. _Biomed. Signal Process. Control_ 69, 102886 (2021).
Article Google Scholar * Tzanakis, N. et al. Classification of COPD patients and compliance to recommended treatment in Greece according to GOLD 2017 report: The RELICO study. _BMC
Pulmonary Med._ 21, 1–9 (2021). Article Google Scholar * Wang, X. et al. Machine learning-enabled risk prediction of chronic obstructive pulmonary disease with unbalanced data. _Comput.
Methods Programs Biomed._ 230, 107340 (2023). Article PubMed Google Scholar * Ananthajothi, K., Rajasekar, P. & Amanullah, M. Enhanced U-Net-based segmentation and heuristically
improved deep neural network for pulmonary emphysema diagnosis. _Sādhanā_ 48(1), 33 (2023). Article Google Scholar * Bhatt, S. P. et al. FEV1/FVC severity stages for chronic obstructive
pulmonary disease. _Am. J. Respir. Crit. Care Med._ 208(6), 676–684 (2023). Article PubMed PubMed Central Google Scholar * Zaidi, S. Z. Y., Akram, M. U., Jameel, A. & Alghamdi, N. S.
Lung segmentation-based pulmonary disease classification using deep neural networks. _IEEE Access_ 9, 125202–125214 (2021). Article Google Scholar * Sun, J. et al. Detection and staging
of chronic obstructive pulmonary disease using a computed tomography–based weakly supervised deep learning approach. _Eur. Radiol._ 32(8), 5319–5329 (2022). Article PubMed Google Scholar
* Peng, J. et al. Exploratory study on classification of chronic obstructive pulmonary disease combining multi-stage feature fusion and machine learning. _BMC Med Inform Decis Making_ 21,
1–9 (2021). Article Google Scholar * Le Trung, K., Nguyen Anh, P. & Han, T. T. A novel method in COPD diagnosing using respiratory signal generation based on CycleGAN and machine
learning. _Comput. Methods Biomech. Biomed. Eng._ 15, 1–6 (2024). Article Google Scholar * Roy, A. & Satija, U. RDLINet: A novel lightweight inception network for respiratory disease
classification using lung sounds. _IEEE Trans. Instrum. Meas._ 72, 1–13 (2023). Google Scholar * Celli, B. R. et al. An updated definition and severity classification of chronic obstructive
pulmonary disease exacerbations: The Rome proposal. _Am. J Respirat. Critic. Care Med._ 204(11), 1251–1258 (2021). Article Google Scholar * Stolz, D. et al. Towards the elimination of
chronic obstructive pulmonary disease: A lancet commission. _The Lancet_ 400(10356), 921–972 (2022). Article Google Scholar * Naqvi, S. Z. H. & Choudhry, M. A. An automated system for
classification of chronic obstructive pulmonary disease and pneumonia patients using lung sound analysis. _Sensors_ 20(22), 6512 (2020). Article ADS PubMed PubMed Central Google Scholar
* Makimoto, K. et al. Comparison of feature selection methods and machine learning classifiers for predicting chronic obstructive pulmonary disease using texture-based CT lung radiomic
features. _Acad. Radiol._ 30(5), 900–910 (2023). Article PubMed Google Scholar * Lakshman Narayana, V., Lakshmi Patibandla, R. S. M., Pavani, V., & Radhika, P. (2022). Optimized
nature-inspired computing algorithms for lung disorder detection. In _Nature-Inspired Intelligent Computing Techniques in Bioinformatics_ (pp. 103–118). Singapore: Springer Download
references ACKNOWLEDGEMENTS The author extends the appreciation to the Deanship of Postgraduate Studies and Scientific Research at Majmaah University for funding this research work through
the project number R-2025-1799. FUNDING No funding received for this research work. AUTHOR INFORMATION AUTHORS AND AFFILIATIONS * Department of Biomedical Engineering, E.G.S. Pillay
Engineering College, Nagapattinam, Tamil Nadu, 611002, India S. Chitra * Department of Medical Equipment Technology, College of Applied Medical Sciences, Majmaah University, Al Majmaah,
11952, Saudi Arabia Tariq Mohammed Alqahtani, Abdulrahman Alduraywish & Mohamed Yacin Sikkandar Authors * S. Chitra View author publications You can also search for this author inPubMed
Google Scholar * Tariq Mohammed Alqahtani View author publications You can also search for this author inPubMed Google Scholar * Abdulrahman Alduraywish View author publications You can also
search for this author inPubMed Google Scholar * Mohamed Yacin Sikkandar View author publications You can also search for this author inPubMed Google Scholar CONTRIBUTIONS All the authors
contributed to this research work in terms of concept creation, conduct of the research work, and manuscript preparation. CORRESPONDING AUTHOR Correspondence to S. Chitra. ETHICS
DECLARATIONS ETHICS APPROVAL AND CONSENT TO PARTICIPATE Not applicable. CONSENT FOR PUBLICATION Not applicable. COMPETING INTERESTS The authors declare no competing interests. ADDITIONAL
INFORMATION PUBLISHER’S NOTE Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. RIGHTS AND PERMISSIONS OPEN ACCESS This
article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction
in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the
licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article
are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and
your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this
licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/. Reprints and permissions ABOUT THIS ARTICLE CITE THIS ARTICLE Chitra, S., Alqahtani, T.M., Alduraywish, A. _et al._ A robust
chronic obstructive pulmonary disease classification model using dragonfly optimized kernel extreme learning machine. _Sci Rep_ 15, 18702 (2025). https://doi.org/10.1038/s41598-025-02952-6
Download citation * Received: 08 October 2024 * Accepted: 16 May 2025 * Published: 28 May 2025 * DOI: https://doi.org/10.1038/s41598-025-02952-6 SHARE THIS ARTICLE Anyone you share the
following link with will be able to read this content: Get shareable link Sorry, a shareable link is not currently available for this article. Copy to clipboard Provided by the Springer
Nature SharedIt content-sharing initiative KEYWORDS * Chronic obstructive pulmonary disease (COPD) * Bilateral filter * UNet * AlexNet * SuperCut * Kernel extreme learning machine (KELM) *
Dragonfly optimization